तकनीकी विवरण
हमने की गई मुख्य सरलीकरण यह है कि हमने ग्रेडियेंट बूस्टिंग को एक न्यूरल नेटवर्क के रूप में उपयोग किया। सामाजिक समाज में न्यूरल नेटवर्कों के साथ स्पष्ट परिचय होता है, इसलिए हमने बूस्टिंग क्या है, इसकी व्याख्या करने में परेशान नहीं होने का फैसला किया, क्योंकि किसी को भी फर्क नहीं पड़ता।
इसलिए, हमने सभी की पसंदीदा Yandex CatBoost का उपयोग किया। क्योंकि यह तेजी से काम करता है और प्रशिक्षण देने में आसान है।
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
अंतिम टोटल F1 स्कोर परीक्षण सेट पर 64 प्रतिशत था। कृपया ध्यान दें, यह बहु-वर्गीकरण है! हम बूलियन चर से नहीं पूर्वानुमान कर रहे हैं, बल्कि कक्षाएँ, जिनमें 80 हैं। हमने डेटा से 10 देशों को हटाने का निर्णय लिया क्योंकि उनमें 1000 से कम प्रतिसादी थे। तुर्की ने अपने प्रश्नों को बहुत बदल दिया था, इसलिए हमने उसे डेटा से हटा दिया।
टोटल F1 को और भी बेहतर बनाना संभव था, लेकिन इसके लिए और अधिक समय की आवश्यकता थी। सिद्धांततः, अगर हम सभी प्रश्नों को खिलाते, तो हमें तुरंत 92% की सटीकता मिलती! कुछ प्रश्न मॉडल के लिए संकेत हो सकते हैं, लेकिन मैं आगे की सुधार की कोई बात नहीं देखता। विशेषज्ञि क्षेत्रों में डेटा को और बढ़ाना भी अच्छा नहीं लगता। किसी भी प्रकार में, लोग अपने जीवन मूल्यों के आधार पर अपने समूहों में जुटते हैं।
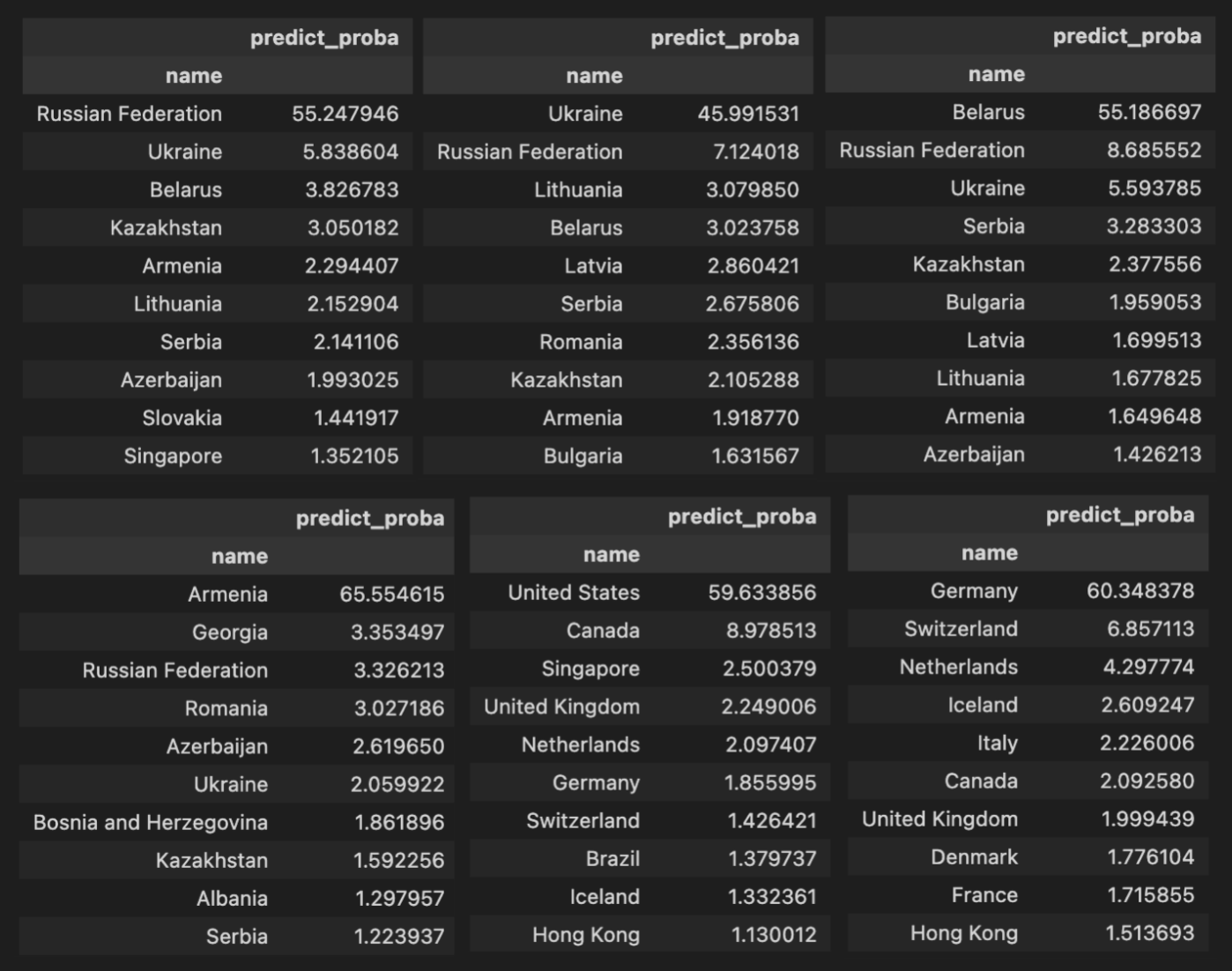
यहाँ कुछ देशों के उदाहरण हैं। प्रत्येक तालिका देश द्वारा डेटा की फिल्टरिंग का प्रतिनिधित्व करती है। और परीक्षण सेट में सभी देशों के लिए मॉडल की समग्र मूल्यांकन करती है। उदाहरण के लिए, पहली तालिका परीक्षण सेट में रूस से समीक्षकों की प्रतिक्रियाओं की प्रतिनिधित्व करती है और उनकी प्रतिक्रियाओं के आधार पर मॉडल की उत्तरें दर्शाती है।
इसलिए, हमने सभी की पसंदीदा Yandex CatBoost का उपयोग किया। क्योंकि यह तेजी से काम करता है और प्रशिक्षण देने में आसान है।
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
अंतिम टोटल F1 स्कोर परीक्षण सेट पर 64 प्रतिशत था। कृपया ध्यान दें, यह बहु-वर्गीकरण है! हम बूलियन चर से नहीं पूर्वानुमान कर रहे हैं, बल्कि कक्षाएँ, जिनमें 80 हैं। हमने डेटा से 10 देशों को हटाने का निर्णय लिया क्योंकि उनमें 1000 से कम प्रतिसादी थे। तुर्की ने अपने प्रश्नों को बहुत बदल दिया था, इसलिए हमने उसे डेटा से हटा दिया।
टोटल F1 को और भी बेहतर बनाना संभव था, लेकिन इसके लिए और अधिक समय की आवश्यकता थी। सिद्धांततः, अगर हम सभी प्रश्नों को खिलाते, तो हमें तुरंत 92% की सटीकता मिलती! कुछ प्रश्न मॉडल के लिए संकेत हो सकते हैं, लेकिन मैं आगे की सुधार की कोई बात नहीं देखता। विशेषज्ञि क्षेत्रों में डेटा को और बढ़ाना भी अच्छा नहीं लगता। किसी भी प्रकार में, लोग अपने जीवन मूल्यों के आधार पर अपने समूहों में जुटते हैं।
गलती मैट्रिक्स
यहाँ कुछ रोचक चीजें होती हैं। हम देख सकते हैं कि मॉडल कौनसे देशों को सबसे ज्यादा गलती करता है। लेकिन आप सवाल को भी फिर से आकर्षित कर सकते हैं और पूछ सकते हैं कि कौनसे देश आपस में सबसे ज्यादा समान हैं, क्योंकि मॉडल उनके नागरिकों को गलती से समझ जाता है।यहाँ कुछ देशों के उदाहरण हैं। प्रत्येक तालिका देश द्वारा डेटा की फिल्टरिंग का प्रतिनिधित्व करती है। और परीक्षण सेट में सभी देशों के लिए मॉडल की समग्र मूल्यांकन करती है। उदाहरण के लिए, पहली तालिका परीक्षण सेट में रूस से समीक्षकों की प्रतिक्रियाओं की प्रतिनिधित्व करती है और उनकी प्रतिक्रियाओं के आधार पर मॉडल की उत्तरें दर्शाती है।