Detalhes Técnicos
A principal simplificação que fizemos foi chamar o aumento de gradiente de rede neural. Uma vez que há uma clara familiaridade com redes neurais na sociedade, decidimos não nos preocupar em explicar o que é o aumento de gradiente, já que ninguém se importa.
Portanto, usamos o CatBoost da Yandex, o favorito de todos. Porque ele funciona rapidamente e é fácil de treinar.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
A pontuação final de Total F1 foi de 64% no conjunto de testes. Observe que esta é uma classificação multi-classe! Não estamos prevendo uma variável booleana, mas sim classes, das quais existem 80. Decidimos remover 10 países dos dados porque tinham menos de 1000 respondentes. A Turquia modificou bastante suas perguntas, então simplesmente a removemos dos dados.
Era possível melhorar ainda mais a pontuação de Total F1, mas isso levaria muito tempo. Em princípio, se alimentássemos todas as perguntas, alcançaríamos uma precisão de 92% imediatamente! Algumas perguntas podem ser dicas para o modelo, mas não vejo sentido em melhorias adicionais. Além disso, não era desejável fazer a pesquisa muito longa. De qualquer forma, as pessoas são agrupadas com base em seus valores de vida.
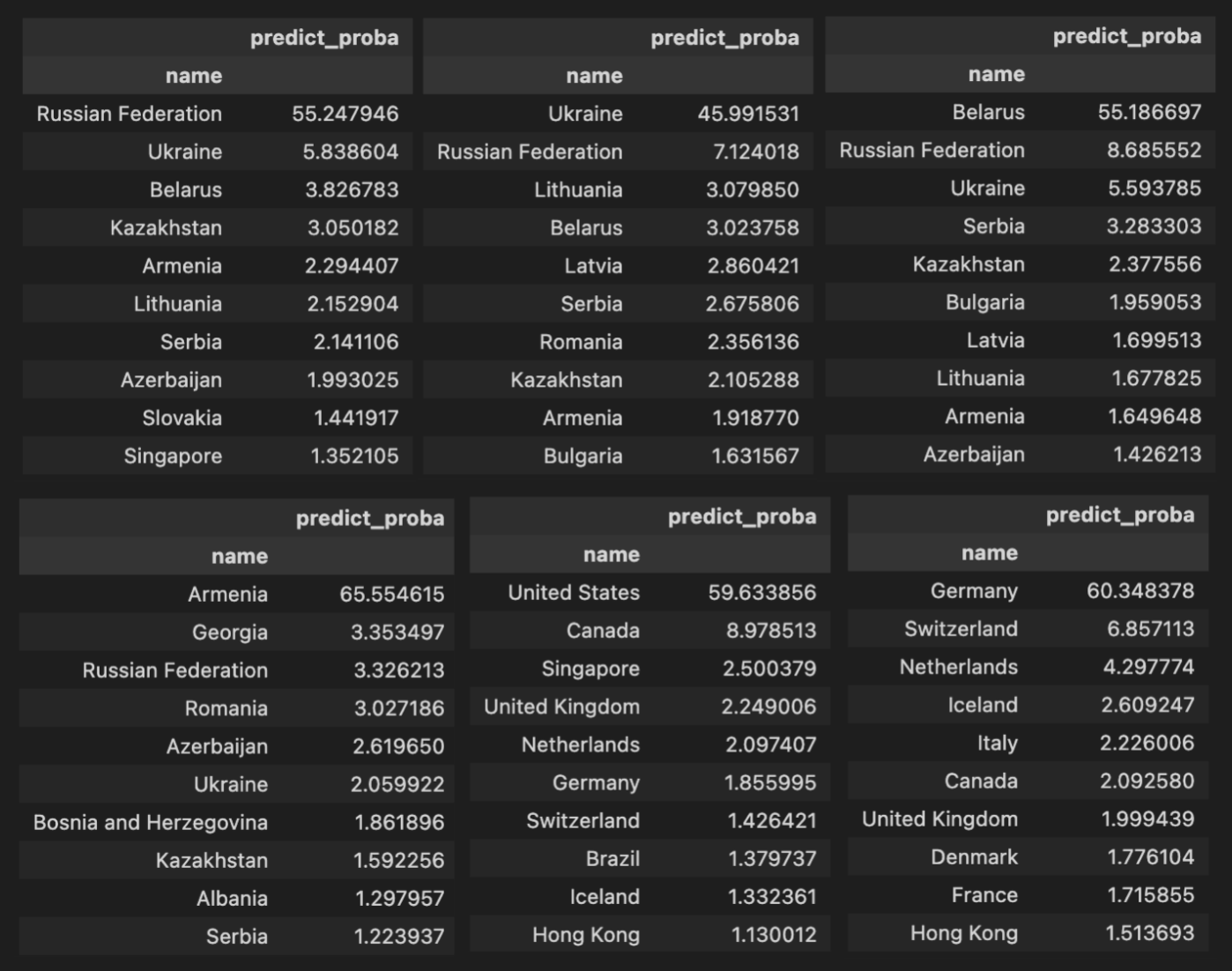
Aqui estão exemplos de alguns países. Cada tabela representa a filtragem de dados por país. E a avaliação global do modelo para todos os países no conjunto de testes. Por exemplo, a primeira tabela representa os entrevistados da Rússia no conjunto de testes e as respostas do modelo com base em suas respostas.
Portanto, usamos o CatBoost da Yandex, o favorito de todos. Porque ele funciona rapidamente e é fácil de treinar.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
A pontuação final de Total F1 foi de 64% no conjunto de testes. Observe que esta é uma classificação multi-classe! Não estamos prevendo uma variável booleana, mas sim classes, das quais existem 80. Decidimos remover 10 países dos dados porque tinham menos de 1000 respondentes. A Turquia modificou bastante suas perguntas, então simplesmente a removemos dos dados.
Era possível melhorar ainda mais a pontuação de Total F1, mas isso levaria muito tempo. Em princípio, se alimentássemos todas as perguntas, alcançaríamos uma precisão de 92% imediatamente! Algumas perguntas podem ser dicas para o modelo, mas não vejo sentido em melhorias adicionais. Além disso, não era desejável fazer a pesquisa muito longa. De qualquer forma, as pessoas são agrupadas com base em seus valores de vida.
Matriz de Confusão
Aqui acontece algo interessante. Podemos ver quais países o modelo confunde com mais frequência. Mas também é possível reformular a pergunta e perguntar quais países se parecem mais entre si, já que o modelo confunde seus cidadãos.Aqui estão exemplos de alguns países. Cada tabela representa a filtragem de dados por país. E a avaliação global do modelo para todos os países no conjunto de testes. Por exemplo, a primeira tabela representa os entrevistados da Rússia no conjunto de testes e as respostas do modelo com base em suas respostas.