Технические подробности
Главное упрощение которые мы сделали — это называние градиентного бустинга нейронной сеткой. Так как в обществе однозначно сложилось ознакомленность в сторону термина нейронных сетей, решили не быть занудами с пояснением что такое бустинг так как всем пофиг.
Значит мы использовали любимый всеми CatBoost от Яндекса. Потому что он быстро работает и прост в обучении.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
Финальный Total F1 был равен 64 процентам на тестовой выборке. Обращаю внимание, что это мултикласс! Мы предсказываем не булеву переменную, a классы, которых было целых 80 штук. 10 стран из данных было решено удалить, так как там было меньше 1000 респондентов. Турция очень изменила свои вопросы, поэтому ee просто удалили из данных.
Можно было и дальше растить Total F1, но на это было уже жалко времени. В принципе если скормить все вопросы, то выходила точность 92% c первого раза! Возможно часть вопросов были спойлерами для модели, но смысла в наращивании дальше я не вижу. Так же делать слишком длинную анкету не хотелось. В любом случае человек попадает в свой кластер по жизненным ценностям.
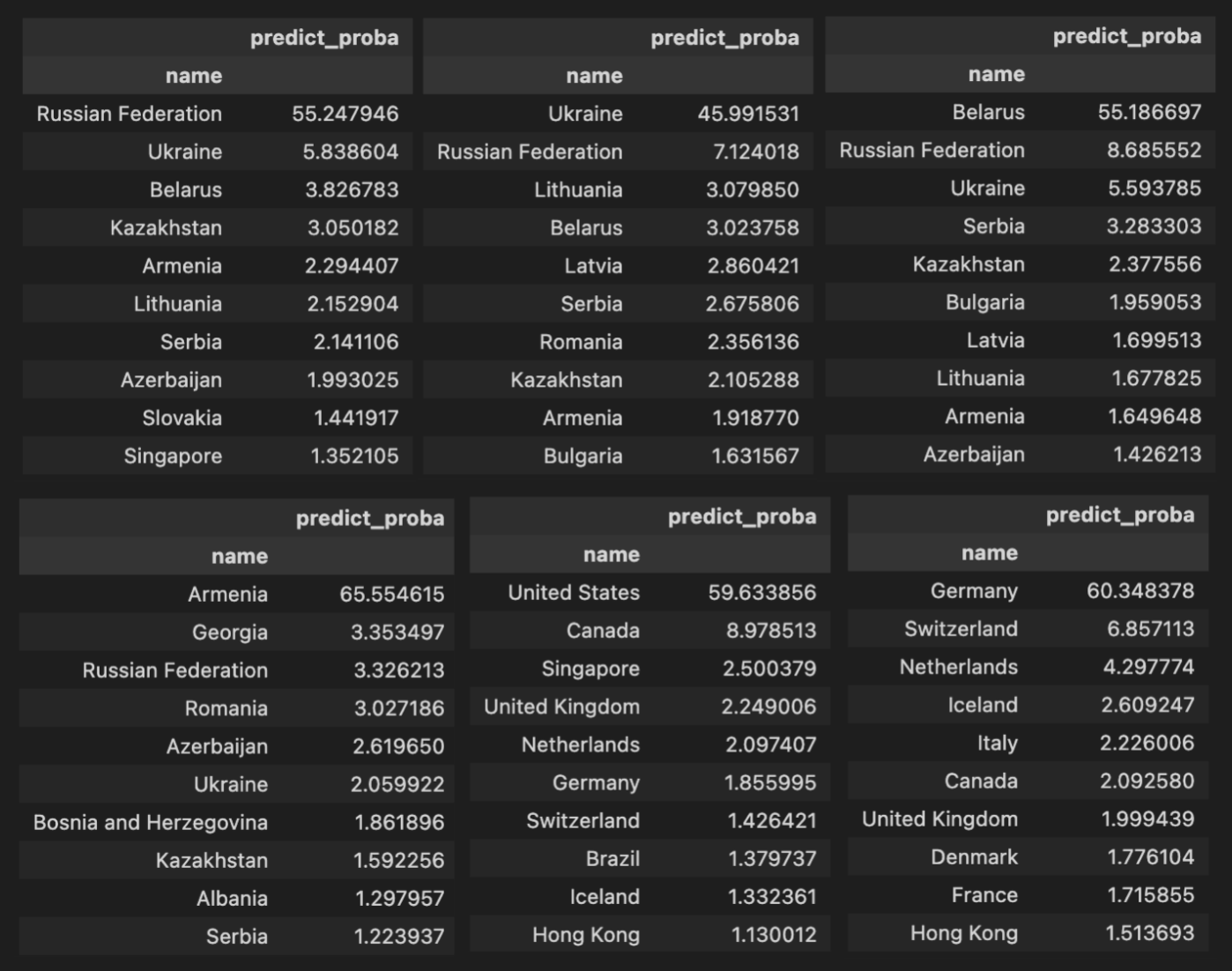
Вот примеры некоторых стран. Каждая таблица это фильтрация таблицы по стране. И суммарная оценка модели по всем странам из тестовой выборки. Например в первой таблице это респонденты из России из тестовой выборки и ответы модели по их ответам.
Значит мы использовали любимый всеми CatBoost от Яндекса. Потому что он быстро работает и прост в обучении.
loss_function - MultiClass
eval_metric - TotalF1
test_size - 40%
Финальный Total F1 был равен 64 процентам на тестовой выборке. Обращаю внимание, что это мултикласс! Мы предсказываем не булеву переменную, a классы, которых было целых 80 штук. 10 стран из данных было решено удалить, так как там было меньше 1000 респондентов. Турция очень изменила свои вопросы, поэтому ee просто удалили из данных.
Можно было и дальше растить Total F1, но на это было уже жалко времени. В принципе если скормить все вопросы, то выходила точность 92% c первого раза! Возможно часть вопросов были спойлерами для модели, но смысла в наращивании дальше я не вижу. Так же делать слишком длинную анкету не хотелось. В любом случае человек попадает в свой кластер по жизненным ценностям.
Матрица ошибок
Тут интересная штука выходит, можно посмотреть с какими странами модель ошибаеться чаще всего. Но тут же можно переформулировать вопрос и сказать какие странны похожи дргу на друга, раз модель путает их граждан.Вот примеры некоторых стран. Каждая таблица это фильтрация таблицы по стране. И суммарная оценка модели по всем странам из тестовой выборки. Например в первой таблице это респонденты из России из тестовой выборки и ответы модели по их ответам.